In order to see if you can run any LLM model on your system, refer to the information below to see our recommendations for running LLMs on your system.
As of the time of writing, this list only covers systems running NVIDIA and AMD GPUs with ROCm support. If you are using a Intel GPU, Apple Silicon, or a AMD GPU that does not support ROCm, our recommendation is to either use KoboldCPP or use cloud hosting.
For AMD Users with ROCm support
If you have a AMD GPU that supports ROCm, you are limited to running YellowRoseCx's fork of KoboldCPP or using cloud hosting.
¶ Find How Much VRAM You Have
¶ Windows
¶ Windows 10/11
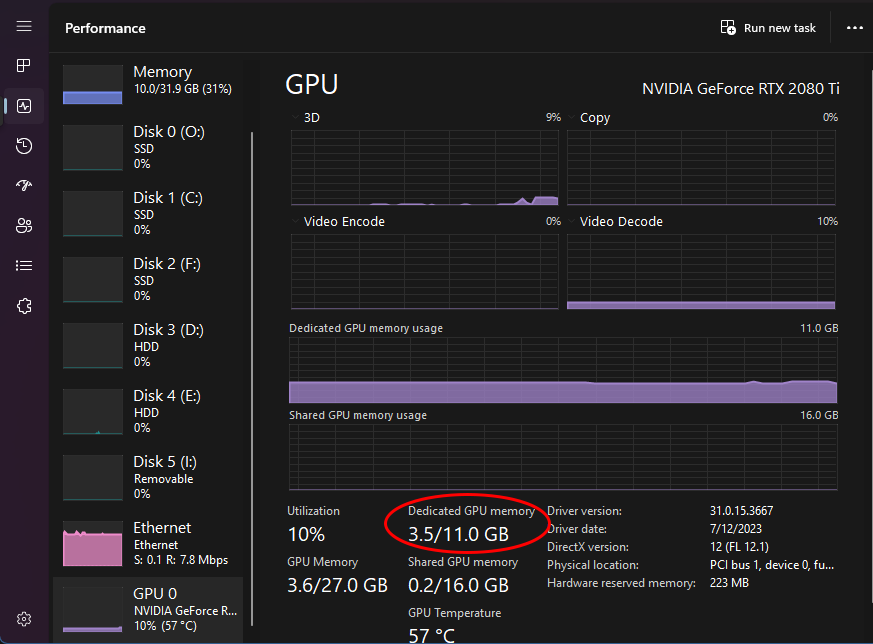
Open Task Manager, go to Performance, select your GPU and see Dedicated GPU memory.
¶ Windows 8.1 and lower
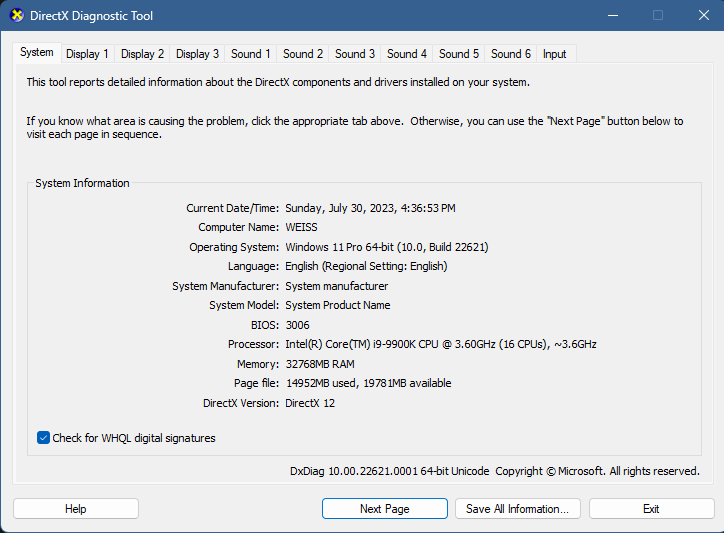
- Press Win+R on your keyboard, type
dxdiagand hit Enter. You should see something similar to this screen below.
- Click on Display 1 (or any display really) and you should see something similar to this screen below.
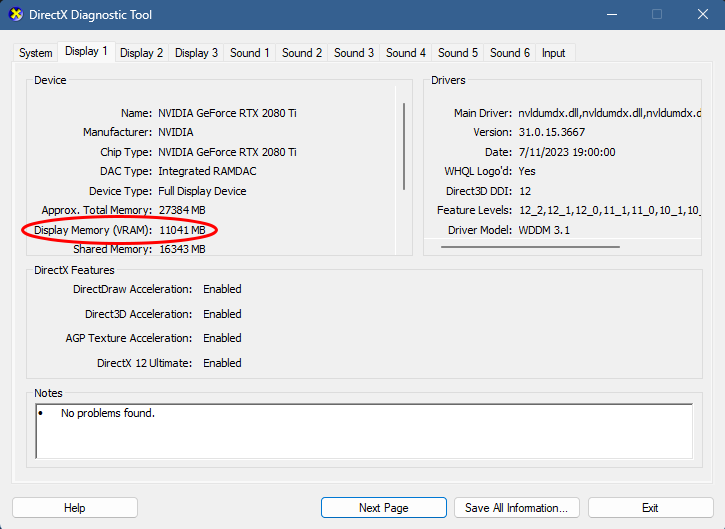
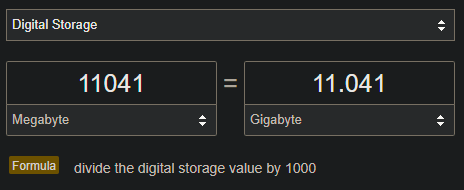
- Put the number of MB you have under Display Memory (VRAM) and Google X MB to GB (replace X with the value of MB you have). You should roughly get how much VRAM there is on your GPU.
¶ Linux
This guide is for NVIDIA GPUs only.
Install nvtop onto your system and run it (using nvtop). You should see how much VRAM you have to the top-right of the nvtop session.
¶ System Recommendations
¶ Integrated Graphics to 6GB VRAM
If your system uses an integrated GPU (typically Intel or AMD) or has a GPU less than 6GB VRAM, you can:
- Use KoboldCPP.
This depends on how much RAM you have on your system. See Task Manager to see how much RAM you have.
¶ 6GB VRAM to 10GB VRAM
If your system has either more than 6GB VRAM but less than 10GB VRAM, you can either use the steps mentioned previously or you can:
- Use KoboldAI (using 4-bit or lower parameter model).
- Use Oobabooga (using
exllama_HFor lower parameter model).
¶ 10GB VRAM to 16GB VRAM
If your system has either more than 10GB VRAM but less than 16GB VRAM, you can either use the steps mentioned previously or you can:
- Use KoboldAI (using 8-bit or lower parameter model).
- Use Oobabooga (using
exllama_HFor lower parameter model)
¶ 16GB VRAM or more
If your system has either 16GB VRAM or more, you can either use the steps mentioned previously or use the following options:
¶ VRAM Requirements for LLMs
All minimums and formulas are all approximate. Minimum VRAM Required accounts for the Max Context Size the model supports. The formula we used to calculate this are as follows:
In which is the size of the model on your hard drive, and is the context multiplier from 1024 using this formula:
Lowering context size can reduce VRAM requirements but lowers the memory the AI can use to remember what you talked about to them.
¶ 16-bit precision
| Parameter Size | Min. VRAM Required |
|---|---|
| 6B | ~17 GB |
| 7B | ~18 GB |
| 13B | ~26 GB |
¶ 8-bit precision
| Parameter Size | Min. VRAM Required |
|---|---|
| 6B | ~9 GB |
| 7B | ~10 GB |
| 13B | ~20 GB |
¶ 4-bit precision (GPTQ)
| Parameter Size | Min. VRAM Required |
|---|---|
| 6B | ~5 GB |
| 7B | ~6 GB |
| 13B | ~10 GB |